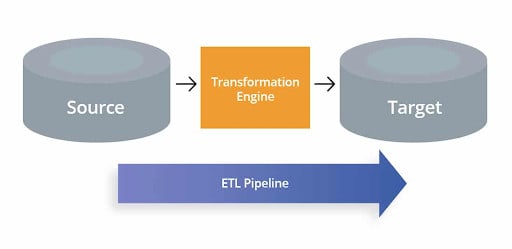
Introduction to ETL Pipeline
An ETL/Data Pipeline is a collection of processes for transferring data from one or more sources into a Database, or a Data Warehouse. The three Interdependent Data Integration methods used to pull data from one Database and move it to another are known as ETL (Extract, Transform, Load). You can empower Reporting & Analysis and obtain actionable business insights once it has been loaded.
- Extract: Extracting data from a source such as a SQL or NoSQL Database, an XML file, or a Cloud platform housing data for Marketing Tools, CRM Systems, or Transactional Systems is known as extracting data.
- Transform: The process of modifying the structure or format of a data to map it with the desired target system is known as transformation.
- Load: Loading data into a destination system, which could be a database, data warehouse, application, such as a CRM Platform, or a Cloud Data Warehouse, Data Lake, or Data Lakehouse from providers like Snowflake, Amazon RedShift, or Google BigQuery.
Benefits of ETL Pipelines
A Data Pipeline, also known as an ETL Pipeline, is used to prepare data for Analytics and Business Intelligence. Source data from diverse systems (CRMs, Social Media Platforms, Web Reporting, etc.) must be migrated, aggregated, and adjusted to meet the parameters and functions of the destination Database in order to deliver relevant insights. An ETL Pipeline can help with:
- Centralizing and Standardizing Data, as well as making it more accessible to analysts and decision-makers.
- Allowing developers to focus on more purposeful work by freeing them from technical implementation tasks for Data Migration and upkeep.
- Data Migration to a Data Warehouse from outdated systems.
- After you’ve exhausted the Information offered by simple transformation, you can go on to more Advanced Analysis with a powerful ETL Reporting Pipeline.
Characteristics of an ETL Pipeline
The move to Cloud-based software services, paired with enhanced ETL Pipelines, has the potential to ease Data Processing for businesses. Companies that presently leverage Batch-based Processing can now shift to a Continuous Processing approach without interrupting their current operations. You can take an incremental & evolutionary approach, instead of going for a rip-and-replace mechanism, which can be costly. You can start with various sectors or particular data types related to the organizations. Finally, ETL-based Data Pipelines empower decision-makers, allowing businesses to obtain a competitive advantage. ETL Pipelines should be able to do the following:
- Continuous Data processing is required.
- Be flexible and adaptable.
- Utilize processing resources that are isolated and self-contained.
- Improve Data Accessibility.
- It should be simple to configure, use and maintain.
Challenges of ETL Pipeline
While ETL is critical, with the exponential growth in Data Sources and Types, constructing and maintaining trustworthy Data Pipelines has become one of the more difficult aspects of Data Engineering.
- Building Pipelines that ensure data veracity is slow and difficult from the start. Complex coding and limited reusability are used to create Data Pipelines. Even if the underlying technology is quite identical, a Data Pipeline designed in one environment cannot be utilized in another, making Data Engineers the bottleneck and tasked with reinventing the wheel every time.
- It’s challenging to manage data quality in increasingly complicated Pipeline Systems aside from Pipeline Construction. Bad Data is frequently permitted to pass undetected through a Pipeline, depreciating the entire Data Collection.
- Data Engineers must build considerable custom code to implement quality checks and validation at every step of the Pipeline in order to maintain quality and assure reliable ETL Reporting insights.
- Finally, as Pipelines become larger and more complicated, firms are faced with a greater operational burden in managing them, making data reliability extremely difficult to maintain.
- The infrastructure for Data Processing must be set up, scaled, restarted, patched, and updated, which takes time and money.
- Due to a lack of visibility and tooling, Pipeline breakdowns are difficult to detect and even more difficult to resolve.
Regardless of these obstacles, a dependable ETL process is essential for every company that wants to be insights-driven. Without ETL solutions that maintain a standard of data reliability, teams all around the company are forced to make decisions based on guesswork and unreliable Metrics and Reports. Data Engineers need tools to streamline and democratize ETL, making the ETL process easier and allowing data teams to develop and leverage their own Data Pipelines to get to insights faster in order to continue to scale.
ETL Pipeline Use Cases
ETL Pipelines are essential for data-driven enterprises, from Data Migration to speedier insights. They save time and effort for data teams by removing mistakes, bottlenecks, and delay, enabling data to flow effortlessly from one system to the next. Here are some of the key yet common scenarios:
- Data Migration from a traditional/old system to a new repository is now possible.
- To achieve a consolidated version of the data, all data sources should be centralised.
- Adding data from another system, such as a Marketing Automation Platform, to data in one system, such as a CRM platform.
- Given that the Data Collection has previously been formatted and converted, providing a solid dataset for Data Analytics tools to readily access a single, Pre-Defined Analytics use case.
- Following HIPAA, CCPA, and GDPR standards given that or provided that users can eliminate any crucial data before loading data in the target system.
Using ETL Pipelines help build a Single Source of Truth and generate a Complete View by breaking down data silos . Users can then use BI tools to extract and communicate meaningful insights, as well as generate Data Visualisations and Dashboards, with data streams powered by ETL Reporting Pipelines.
ETL Pipeline vs Data Pipeline
The full collection of processes applied to data as it goes from one system to another is referred to as a Data Pipeline. ETL Pipelines typically form a type of Data Pipeline because the word “ETL Pipeline” relates to the procedures of Extracting, Converting, and Loading data into a database or a Data Warehouse. However, “Data Pipeline” is a broader phrase that does not always imply Data Modification or even loading into a target database, the loading procedure in a Data Pipeline, for example, the procedure could trigger another process or workflow.
Conclusion
This blog talks about ETL or Data Pipelines in detail. It also provides a brief overview of various use cases, characteristics, and use cases of Data Pipelines.


